To my mind, the most important foundational concept to statistical inference is an appreciation of sampling variability. Chance, del Mas, & Garfield (2004) lay out a vision of what students need to understand and what they should be able to do with that understanding. However, I wouldn’t reach as far as they did. I believe that the core understanding rests on only a small subset of their list.
The main understanding students should have, in my opinion, is that given a population parameter, some values of a sample statistic are more or less likely to than others to be the result of a sample from that population. This should manifest in a student’s ability to make statements about how far a sample statistics is likely to vary from a population parameter, and vice versa.
Developing such an understanding in students is no trivial matter. There seems to be consensus in the statistics education research community that the use of simulations can help develop students’ understanding of sampling variability (Garfield, et. al., 2008).
I particularly like an activity designed by Scheaffer, et. al. (1996) called What is a confidence interval anyway?. The instructor resources presents a scatterplot relating population proportions to their likely sample proportions (Figure 8, page 274).
Printed below is an adaptation of this scatterplot demonstrating how a student might use it to determine that the likely values of a population proportion are between approximately 65% and 75% after determining that their sample proportion is 0.70 from a sample of size 100.
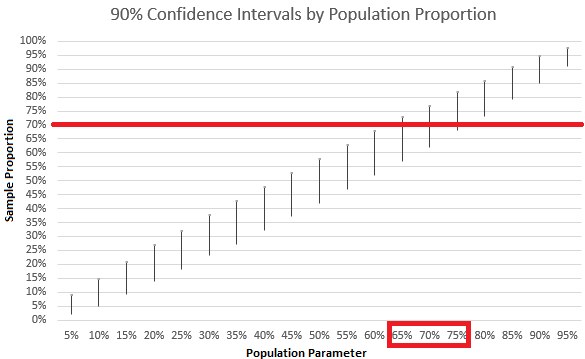
I particularly like this tool as I believe it helps to frame the idea of inference quite nicely. We never know what the true population parameters are. However, the theory of sampling distributions tells us something about how sample statistics behave in relation to those parameters.
Each of the vertical bars represent the likely sample proportions we might get when we sample from a population with the given population proportion. When we take only one sample sample, we can never know for sure the exact value of the population parameter, but certain options become to look increasingly unlikely. Use of this scatterplot may guide students into a more multiplicative conception of a sample (Saldanha & Thompson, 2002).
I believe such an activity can help improve students’ ability to make statements about how far a sample statistics are likely to vary from a population parameter, and vice versa. However, by only focusing on this one learning objecting, as opposed to full list of recommendations by Chance, et. al. (2004), would I be doing a disservice to our students in their future work and studies in statistics, or will this indeed provide a sufficient foundation for them to become statistically literate?
References and further reading:
Chance, B., del Mas, R., & Garfield, J. (2004). Reasoning about sampling distribitions. In The challenge of developing statistical literacy, reasoning and thinking (pp. 295-323). Springer, Dordrecht.
Garfield, J. B., Ben-Zvi, D., Chance, B., Medina, E., Roseth, C., & Zieffler, A. (2008). Learning to Reason About Statistical Inference. In Developing Students’ Statistical Reasoning (pp. 261-288). Springer, Dordrecht.
Saldanha, L., & Thompson, P. (2002). Conceptions of sample and their relationship to statistical inference. Educational studies in mathematics, 51(3), 257-270.
Scheaffer, R.L., Watkins, A., Gnanadesikan, M., Witmer, J.A. (1996). What Is a Confidence Interval Anyway? In Activity-Based Statistics: Instructor Resources (pp. 274-278). Springer, New York, NY.
